Every year, I join a group of friends in a friendly competition to see who can create the best NCAA Men’s College Basketball bracket.
I always pick Purdue to go way too far. (Although, last year, I nearly got it right!) Go Boilers!
And each year, I spend an hour or more reviewing high level data. Based on that, I generally go with my gut.
But this year, I decided to do something different. I wanted to free up that mental capacity and let AI tackle my bracket.
I wanted to challenge AI to come up with the best possible bracket.
Knowing that I would benefit from real-time data and sports news, I opted to try Perplexity. I was intrigued to see if it could handle this task.
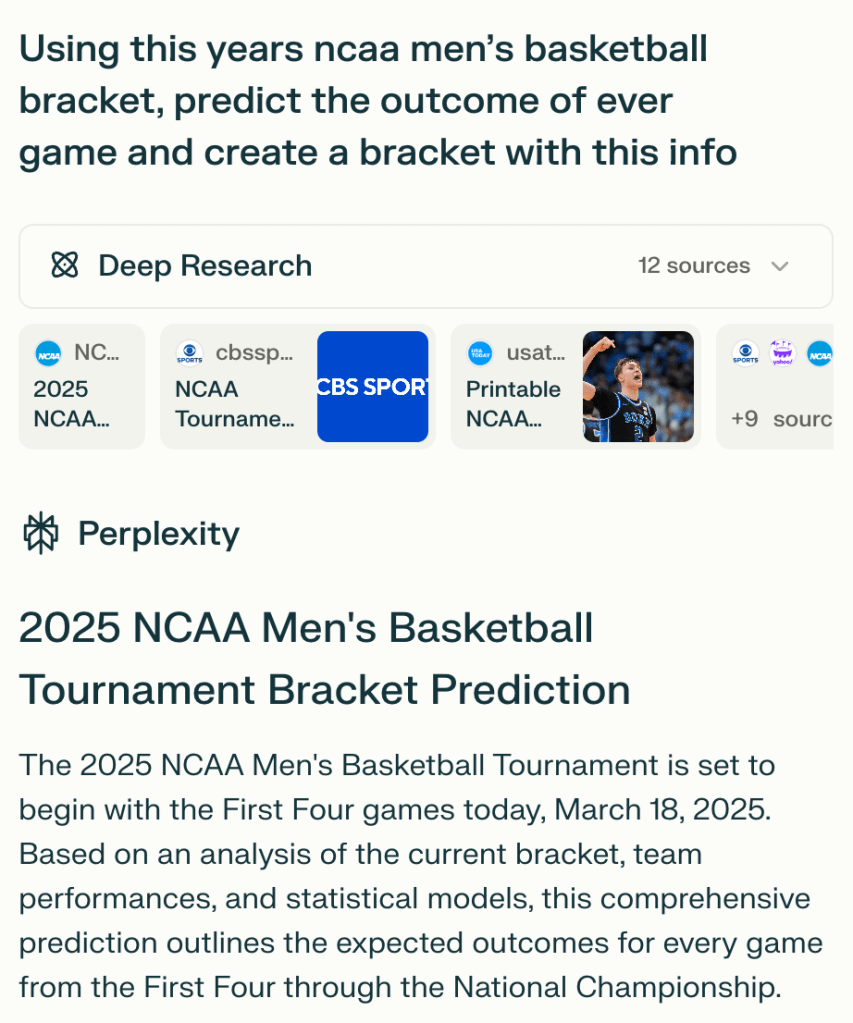
I selected the Deep Research model (using Deep Seek R1) because I wanted to give it time to really go deep on the subject and digest all of the latest information it encountered.
And on top of that, I wanted it’s analysis to be data-driven, leveraging any available statistics.
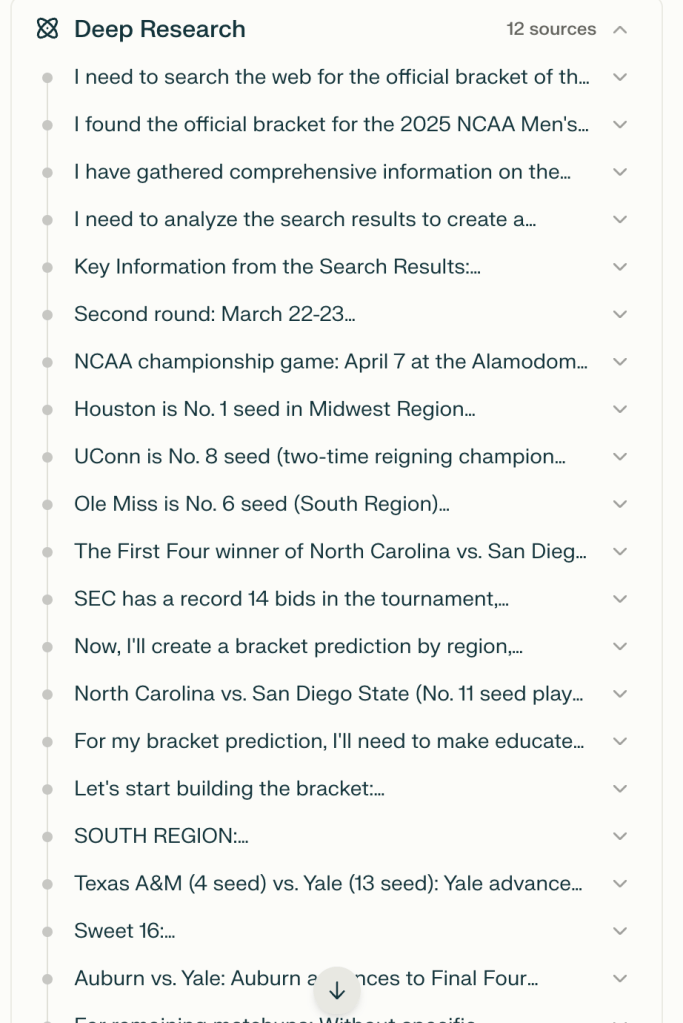
The model then broke my prompt (request) into a bunch of smaller tasks and starts gathering, analyzing, and synthesizing data to help it towards its final goal.

The output (results) looked okay at first glance, I saw nothing that seemed strange.
But, as I continued reading through the output, I saw things that I knew weren’t right.
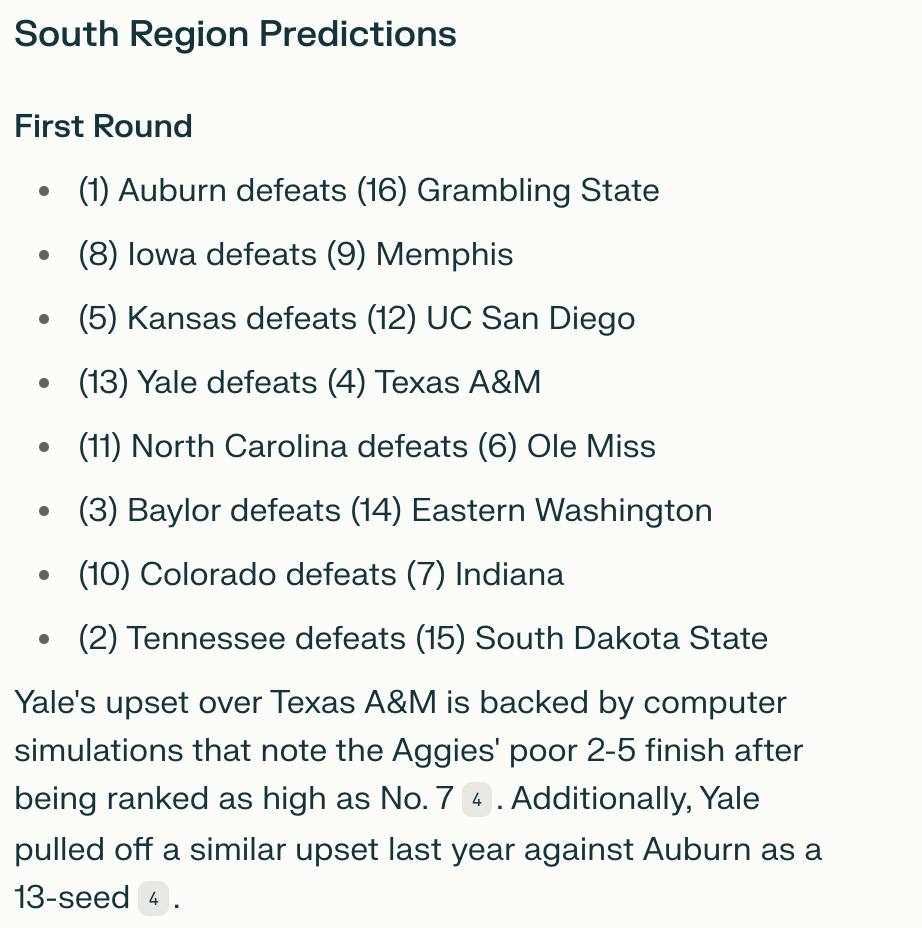
One in particular, I didn’t think Indiana (IU) made the tourney this year. Yet, I wasn’t 100% on that.
But, I did know Purdue was going to play High Point in the first round.
So, I continued until I found the Purdue matchup.

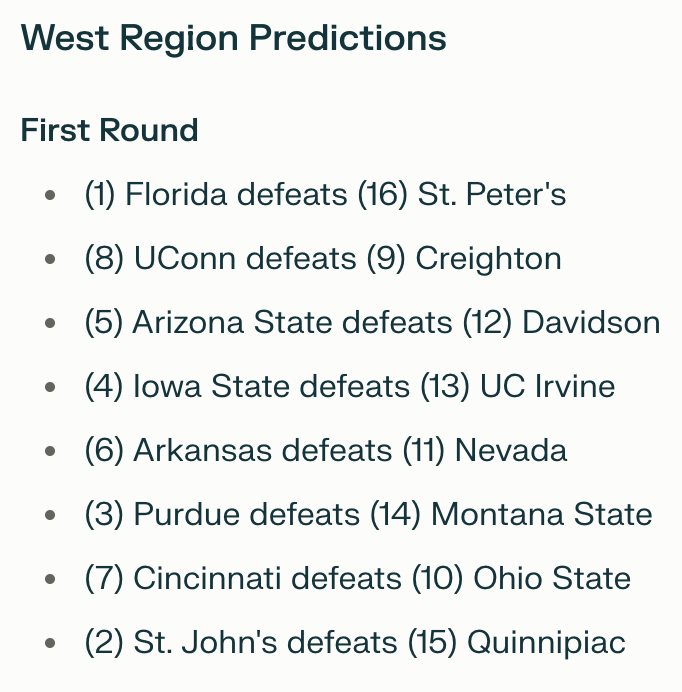
Purdue (3) defeats (14) Montana State.
I knew Purdue was a 4 seed, so this was an immediate red flag. Further, Montana State was not High Point.
Yikes. Perplexity’s output wasn’t factually sound.
Hmm… Perplexity?
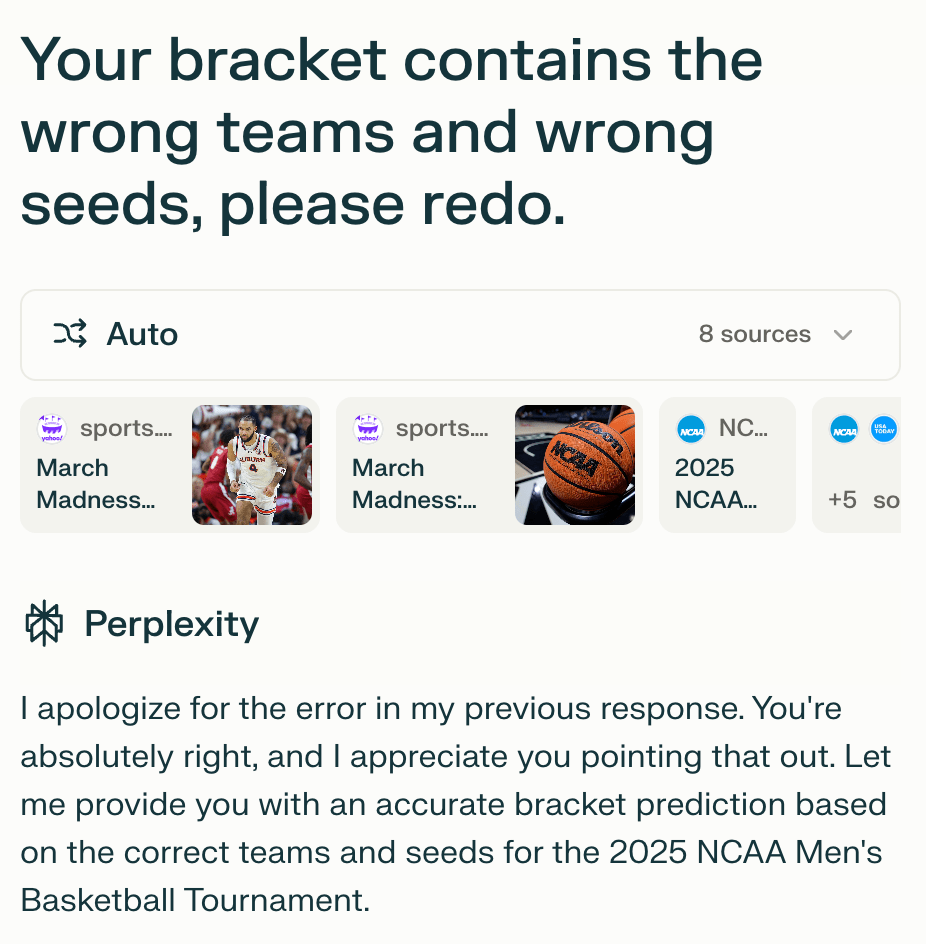
I wanted to give Perplexity a chance to address this, surely it could figure it out, right?
This time I let Perplexity decide what the best model to use would be. I had hoped by previously previous data it would have had enough context to leverage moving forward.
I was wrong.
Again (3) Purdue defeats (14) Montana State.
I looked closer and saw it had updated the (2) team to St. John’s (previously Kansas State), so something had changed. However, it was still outputting data that wasn’t factual.
One more try… maybe Perplexity could figure it out.
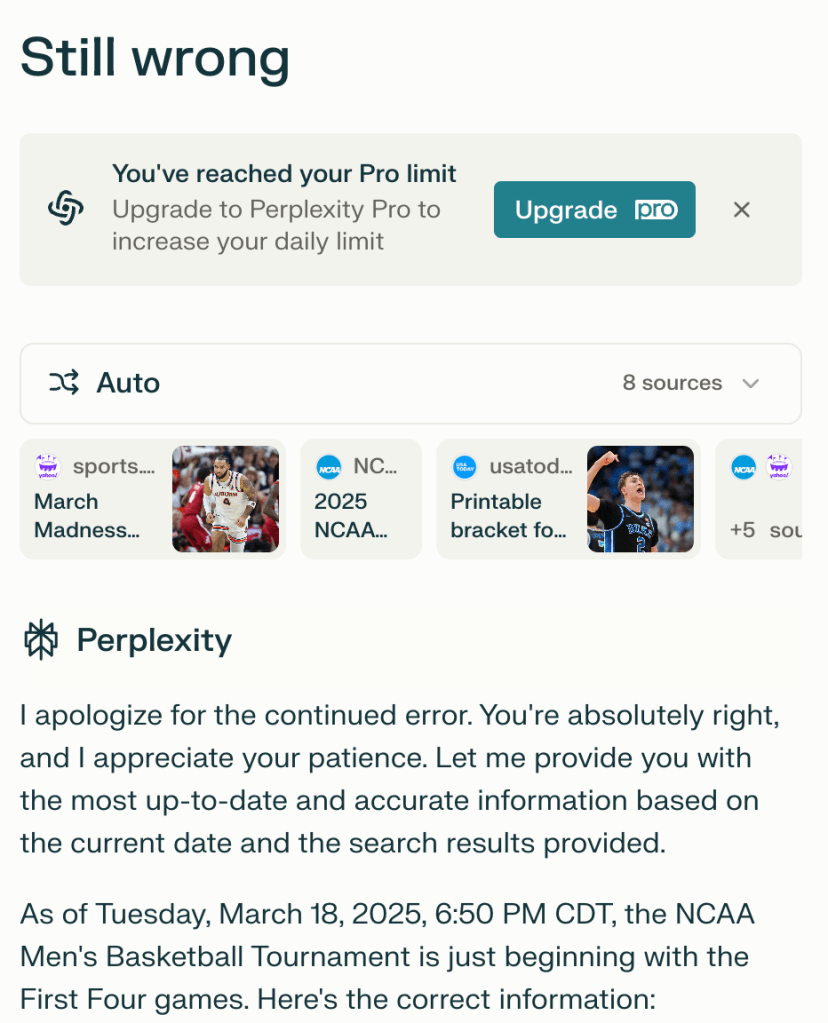
Unfortunately, it never would get it right. And so I decided to abandon this attempt.
48 hours later, and with the bracket deadline looming, I came back to the task.
This time, I would dial in my prompt a bit more and attempt to guide the model to seek out and dig deeply into data, and would use this data to decide which teams would win each respective game.
Feeling that this may have been the missing element of my previous attempt, I went back to Perplexity and prompted:

Oh, and one other thing. I uploaded a .pdf copy of the 2025 bracket as a reference point, and I opted for Deep Research using R1, once again.
While this model was thinking, I opened an additional tab on my browser and navigated to ChatGPT.
Why?
I wanted to simultaneously run the same prompt, as the one I gave Perplexity. I would then review the results and decide which model’s output to use.
I also gave ChatGPT a .pdf copy of the bracket, while toggling on the “Search” and “Reason” buttons. I prompted:

And the model started thinking.
It was interesting to watch the model operate. First, it took the PDF bracket and parsed the data into to the bracket matchups.
From there it went on…

It looked like it might take awhile, so I went back to see if Perplexity was done with its research, analysis, and recommended picks.
Reviewing the Deep Research flow, I found it interesting to see how the model broke down the prompt into smaller tasks to execute, while creating additional tasks, and while gathering and analyzing additional data, as needed.
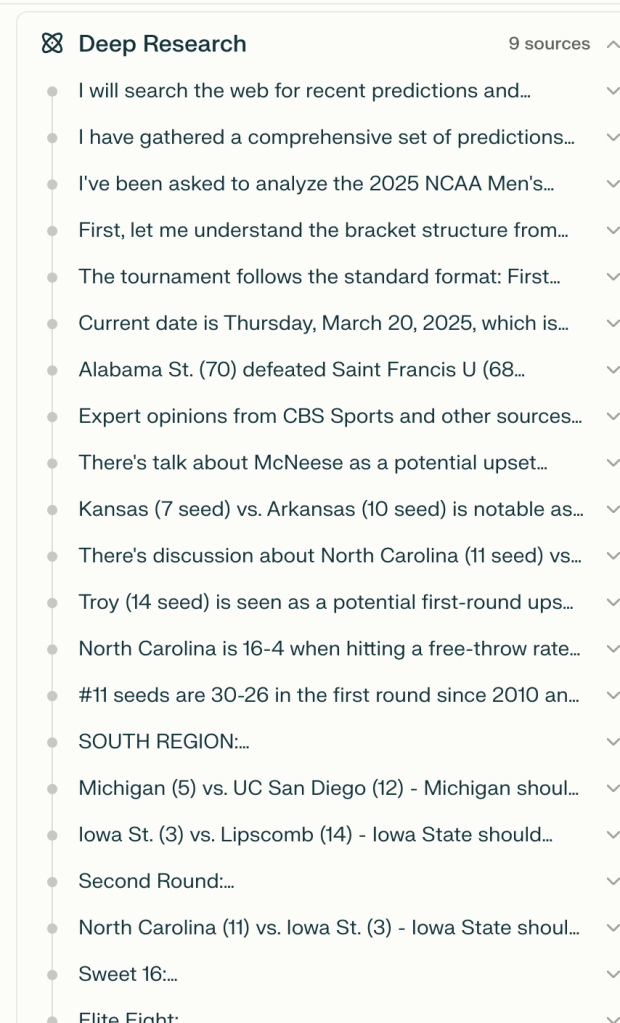
Remembering what the output had been 2 days ago, I was a tiny bit skeptical of what Perplexity would deliver.
However, knowing that I had taken time to craft a more contextual prompt and had given the model a PDF copy of the bracket to reference, I was confident the model would generate a significantly better input.
And so, I was also intrigued.

Now this result seemed reasonable, I knew (8) Louisville would play (9) Creighton in the first game today, so that checked out.
But what did the model’s output say about Purdue.

Yes! (4) Purdue vs. (13) High Point.
And YES!, “the Boilermakers’ size advantage should be decisive.” It usually is, so that sounds great to me!
I was curious, so I continued.
Aside from having my Boilers exiting in the second round, the results seemed pretty sound to me.
Duke wins it all. A few upsets here and there. It all checked out in my mind.
The model gave some supporting reasoning for its decision, which I found helpful, even if it was only sharing a single source per pick (which could have been biased.)

Still, this felt like a pick strategy I could get behind.

I like the importance placed on which team is peaking at the right moment. Knowing that information, I would make this same pick nearly everyday.

Go big 10. This also sounded right to me, albeit 100% ignorant of Montana basketball.

Maybe it is because they beat my Boilermakers in the Championship Final last year, but this reasoning felt highly sound, and likely to happen.
Alright, this output was day-and-night better than the previous attempt.
I liked the result.
But, how did ChatGPT do?
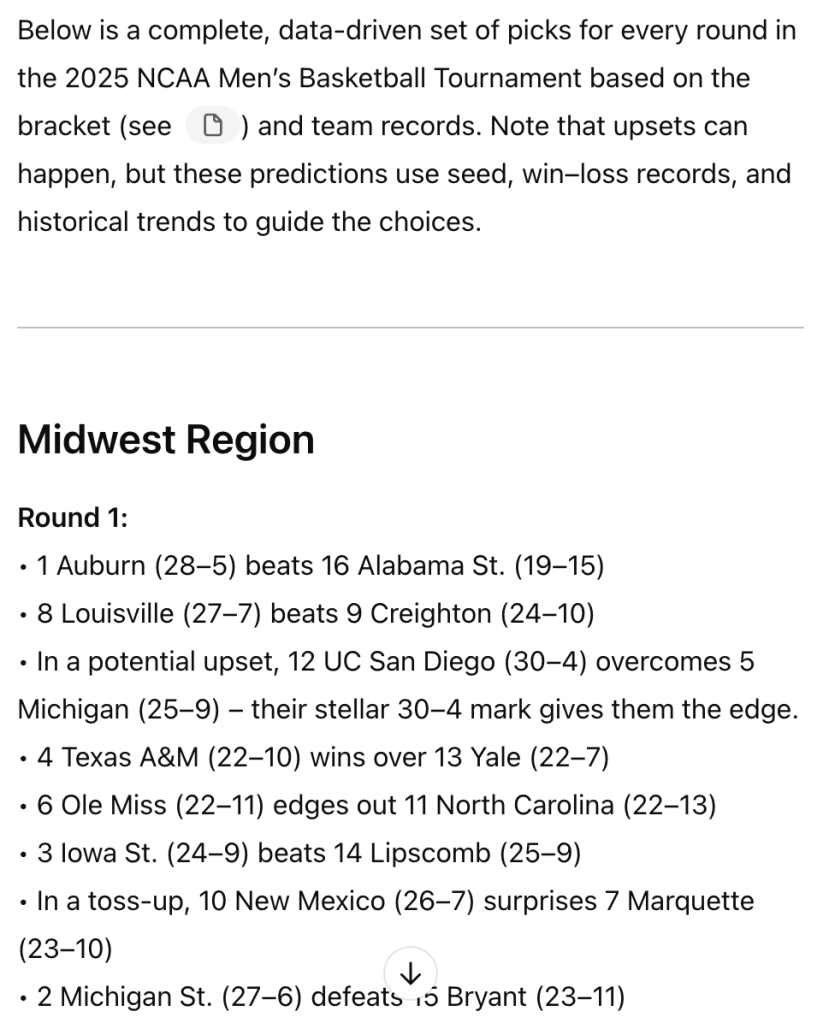
This seemed totally reasonable. I was a little disappointed there was no real explanation or reasoning for any of the picks, aside from UC San Diego upsetting Michigan “their stellar 30-4 mark gives them the edge.”
But, I was undeterred and was not ready to dismiss ChatGPT’s assessment, so I continued.

It picked a few upsets. I was onboard with this, as this is what I expected a highly data heavy analysis would reveal as the correct decision.

Still, not a lot of reasoning being given, but with upsets be suggested, the lover-of-an-underdog-story inside of me liked seeing that.

Ugh! No! Purdue losing to High Point. I’ve seen it happen before, and it isn’t pretty.
And thats when I looked at the clock.
It was 11:09 CST.
I had exactly 6 minutes to lock my picks or I will be locked out from making an entry.
So which model’s output did I choose?
I ended up choosing the output from Perplexity using Deep Seek’s R1 model.
I like how the model provided reasoning instead of providing simply “a” team > “b” team. That resonates with me.
And then each point of reasoning was backed up by a source. And I could see that source link right next to each point. Again, this resonated with me.
So I went with it!
And with less than 6 minutes to go, it was time to input the picks. I was optimistically calm, as I logged in to make my initial selections.
5 minutes to go.
I was still working on inputting the first round, (5) Oregon over (12) Liberty.
4 minutes to go.
I was into the 2nd round, (2) Michigan State over (7) Marquette.
3 minutes to go.
I was into the Sweet 16, (2) St. John’s over (11) Drake.
2 minutes to go, into the elite Elite 8.
1 minute to go, into the Final 4.
30 seconds to go, I input the Championship winner.
I hit submit.
My bracket was live! I had made it.
AI made my bracket.
I am excited to see how it does and will update this entry as the tournament progresses.
As I type this, the first 4 games have been finalized.
The first game, the model picked Louisville over Creighton.

The model got it wrong. It did say it would be a close game, however, Creighton decisively defeated Louisville.

The other 3 games, the model predicted correctly, so its current success rate is 75%.
Will this performance hold?

Leave a comment